An AI-Based Solution For the Blind and for the Visually Impaired
I started working on the developement of the project Lighthouse, few weeks after I have started the project Autopilot-IA. The project was a success and is still under ongoing development. LightHouse is an application designed to offer a unique experience to the visually impaired or blind person and contribute to their well-being. It leverages the latest advances in Artificial Intelligence (AI), especially in one of its subfields, namely, deep learning. The application would allow anyone in possession of a smartphone and without the use of one’s eyesight to know approximately what’s in front of them, what object to look for and provide instructions on how to find it. The innovation of the algorithm stands not only on the latest object detection and localization algorithm, i.e., YOLO, but more importantly, on the many features (modes) that would assist the visually impaired people in their daily life and inside their home.
Motivation
It is observed that more than 1.7 million people in France experience some trouble in their vision. 207000 are highly visually impaired, amongst them 65000 are blind. 90% of people older than 65 are visually impaired. These numbers are expeted to double in 2050. An application for detecting, localizing and finally guiding the end user towards an object . The application will eventually run on a smartphone and the way it works will be explained. The first thing that comes to mind when designing this kind of application is to use a camera as a replacement to our human vision. One can think of the ouput of a camera (video) as a succesion of images that can be utilized to detect, in real time, different objects in the image .
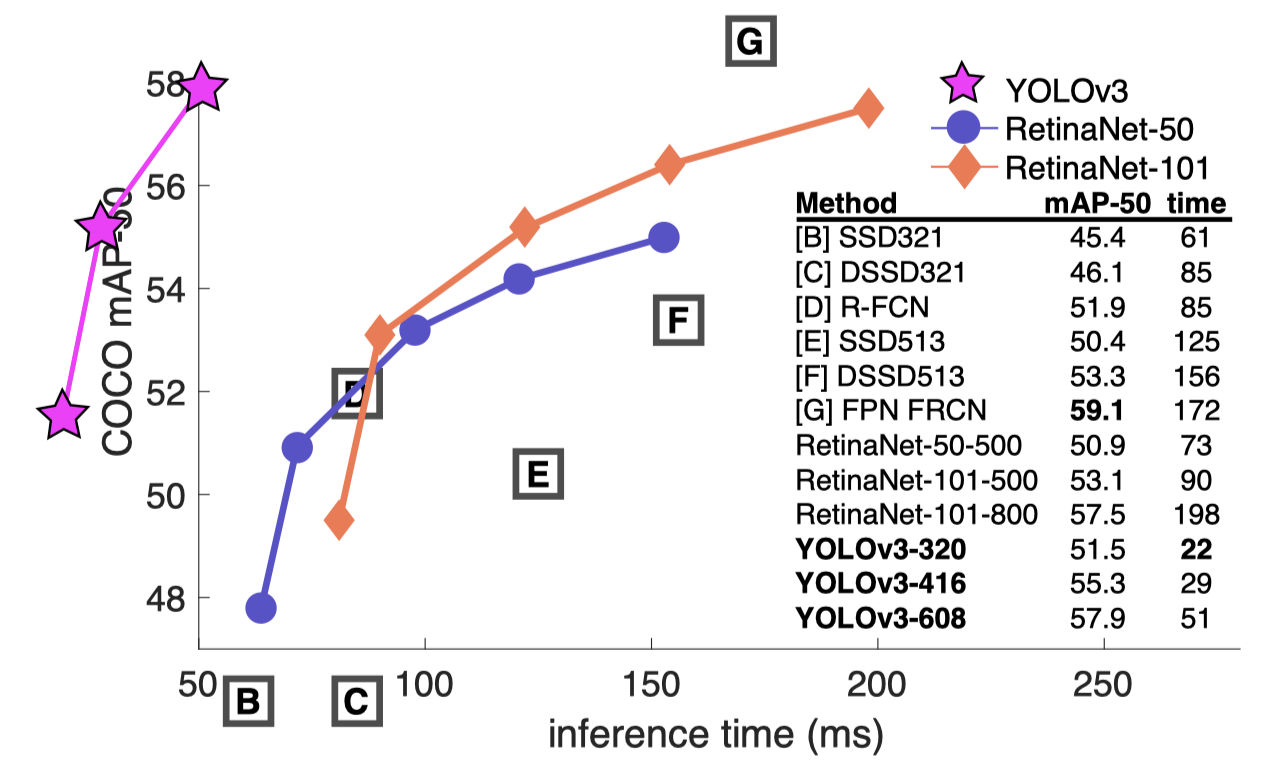
Comparing the performance of YOLO with respect to other detection algorithms in function of mean average precision (mAP) and inference time (ms)
Choice of the object detection neural architecture
Amongst the many object detection and classification algorithms, this last decade has seen convolutional neural network becoming the standard, from architecture ranging from RCNN, SSD, and many others, YOLO is an object detection and classification algorithm which actually presents the best tradeoff in terms of precision and processing time as one can observe in the above benchmark figure, where
- The Y axis represent the mean average precision and the X axis the inference time:
- The inference time is the time necessary to treat one image. You can observe that when compared to other algorithms, YOLO performs better in terms of speed and accuracy.
YOLO uses only convolutional layers, making it a fully convolutional network (FCN). YOLO v3 is based on a deeper architecture of feature extractor called Darknet-53. The number outlines the 53 convolutional layers, each followed by a batch normalization layer and Leaky ReLU activation. In order to prevent a loss of low-level features, often present with pooling, a stride 2 is used to downsample the feature maps. Detection algorithm does not only predict class labels but detects objects’s location as well. It therefore not only classifies the image into a category, but it also detects multiple objects within an image.
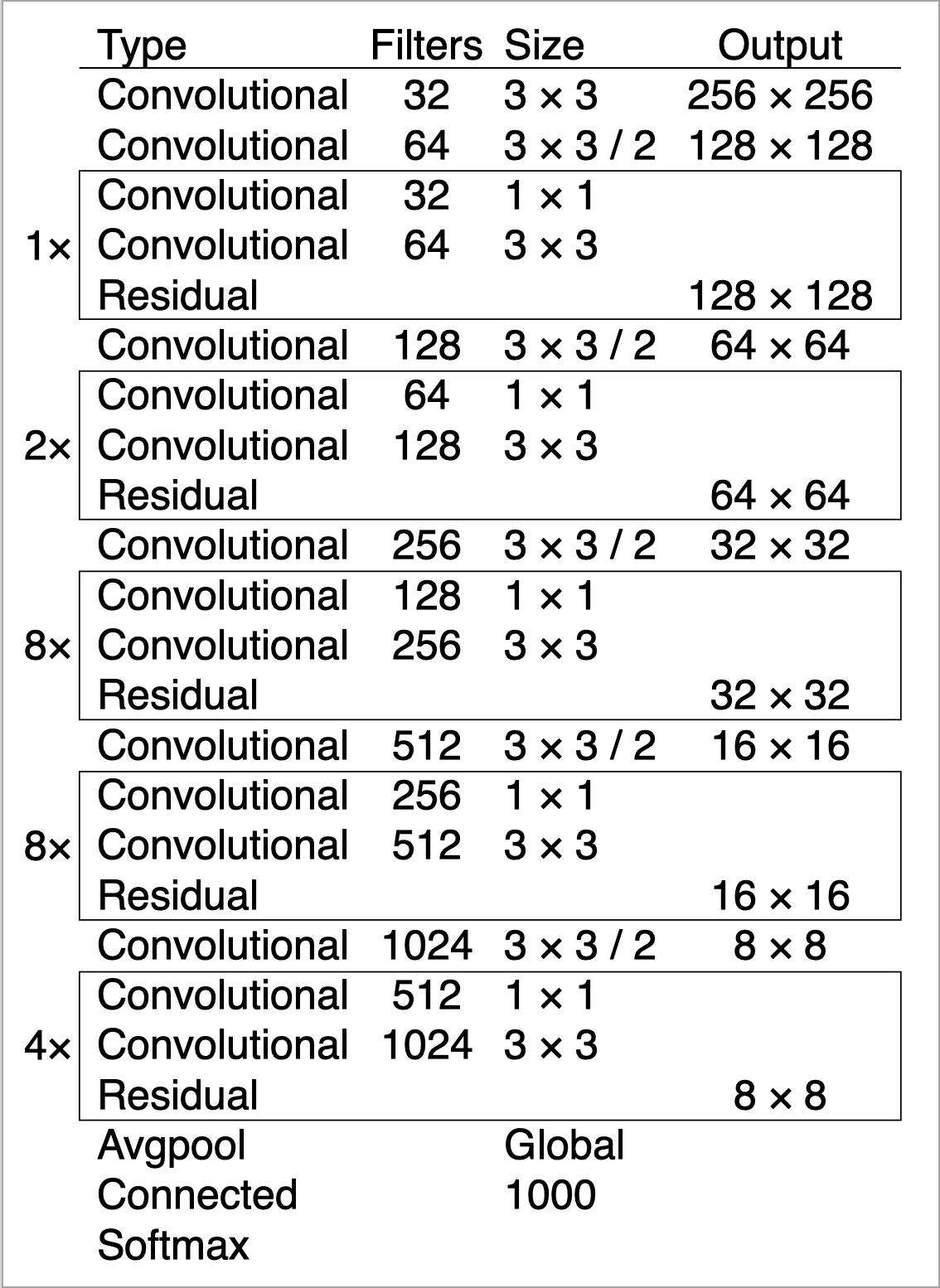
Darknet-53 architecture
Interpretation of the output
I am not going to go through the details of how YOLO works, this can be found in the litterature, I will however focus on a key step to understand the rest of the project. To make it simple, one can think of YOLO as a black box, where :
- the input is a batch of images of shape
(m, 416, 416, 3), wheremis the number of images and - the output is a list of bounding boxes along with the recognized classes. Each bounding box of the detected object is represented by
[c, x, y, w, h, s]. The detected object classc, its tag center(x, y), the width and height of the box given as(w, h), as well as the probabilitysof belonging to a class. - YOLOv3 has been trained to recognise 80 category of objects, amongst them the ones that are present in the figure below.
As you would have probably guessed, the figure below is a sample of what the output image of YOLO would look like.

Output image of YOLO, displaying the bounding boxes around the detected objects. The table indicates the probability class s
We know where a specific object is located in the image and we have a certain confidence about which class it belongs to. Is this enough to guide a blind or visually impaired person to find what they are lookling for?
Answer: The user need to have some sense of
- Orientation and
- Direction
Architecture of the application
Lighthouse is an application designed to run on a smartphone. The way it interact with the user, is through a speech to text (STT) and text to speech (TTS) modules. The way the application works is as follows:
- A module for speech to text recognition lets the user interact with the application by asking a question:
What are you looking for? - The user answers with the object of his interest by saying
I am looking for a cupas un example.cupis the key word here - Once the target is defined, the camera feeds the Yolo network with a set of image (frame) per second
- The Yolo network returns the set of coordinates of the detected objects together with a class probabilities
- From these information we developped three modes, the user of course, will be offered the possibility to choose amongst the three modes
- The application will communicate back with the user with a TTS algorithm.
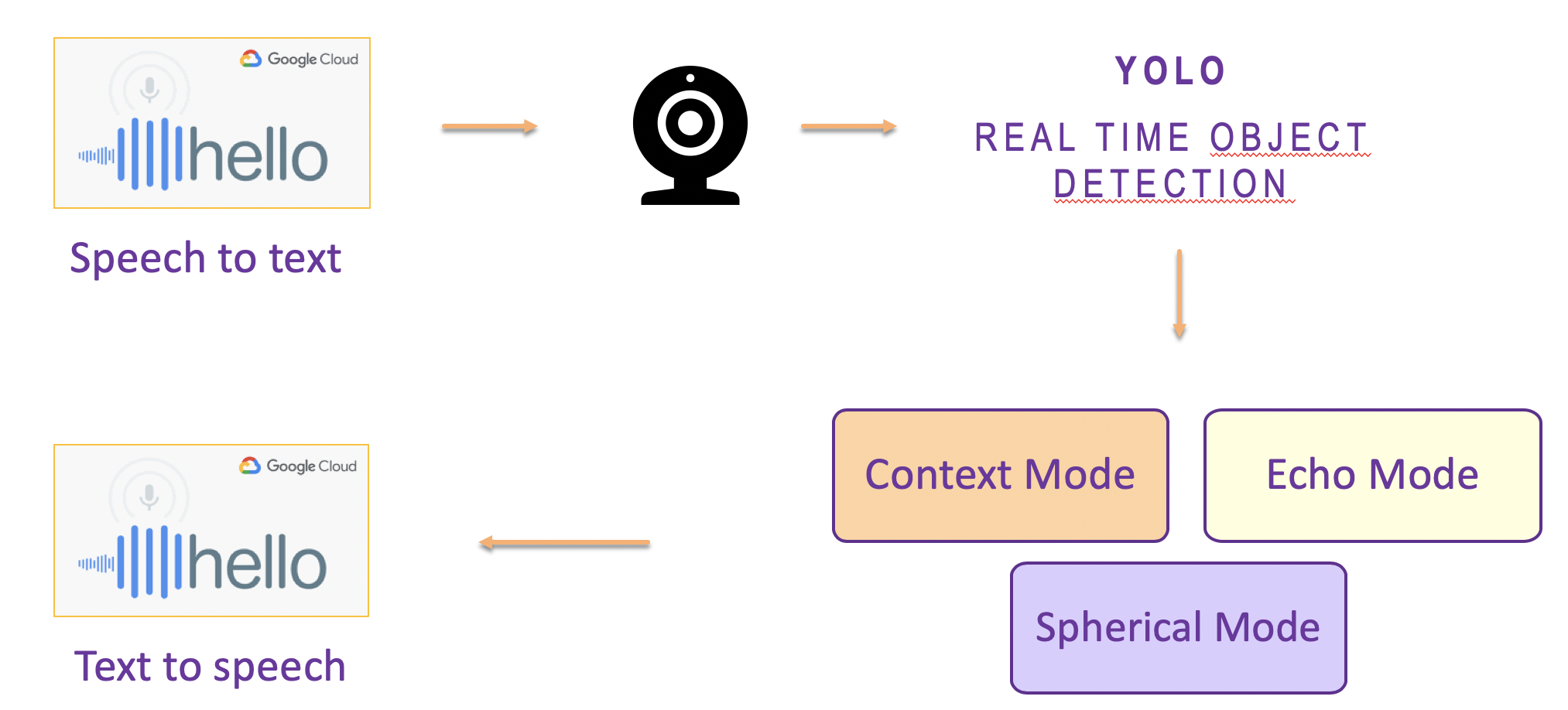
Lighthouse Architecture
Lighthouse Modes
Three modes have been developed to guide the user towards finding the lost objects inside his apartment.
Context Mode
The Context Mode is used by default. This mode exploits the actual setup of the room furniture and the arrangement of different objects to serve as references to guide the user. Once an object has been detected, the angle information together with the depth of the image are used to provide a more precise and complete description of the environment surrounding the object of interest. An algorithm is developped to give sense to all the detected objects with the respect to the targeted one.
Essentially, we identify three types of object association:
- on/under,
- in front/behind and
- left/right.
Therefore, for a question similar to:
where is my bottle? LightHouse will respond:the bottle is on the table, left to the mouse, behind the keyboardas an example.
Stereo vision and disparity map
To understand some important concept regarding the design of this mode, let’s say that we are in front of three objects, any objects in fact, and these objects are placed one after the other. One of the amazing features of the human eye, is the ability to know exactly which objects is the closest to us and which one is the farthest. This happens because we see with both our eyes. Any scene you see from your right only appears to be shifted when seen from the left eye. This shift in the position of objects due to our stereo vision depends on how far the object is from us. The closer it is, the more it gets shifted. With this difference we can calculate the disparity map. The map is given in the same size as the original, however a gradient of black and white color is produced. The whiter the object appears, the closer it is to us, and the darker it appears the farther it is.

Normal image on the right-hand side together with its associated disparity map on the left-hand side
Obtaining the disparity map is important since it will give us the possibility to describe the scene quite accurately. The mode was developed to take into account the disposition of all the objects with respect to the targeted one. If the user triggers this mode, by saying clearly I am looking for a cup. The designed algorithm would understand that you are looking for a cup and give you a scene description as in the figure you can see below

Context Mode in action
One can see on the bottom left-hand side of the figure above a scene description with respect to the targeted object. The message reads
Cup is at the right of Bottle1Cup is at the right of keyboard
Sphere Mode
the Sphere Mode uses the spherical coordinates, that is, to find the object of interest the user is provided with three pieces of information, a pair of angles and a distance. The application will update the user about these information on demand.
The coordinates are given as follows:
- altitude,
- Longitude and
- Latitude
The altitude in our case, is the distance of the target object to the camera. The longitude can be seen as the vertical angle formed between the horizontal sight line (See picture below) and the targeted object. While the latitude is the horizontal angle formed between the heading of the camera and the target. The main information used to calculate the these angles are as follows
- Horizontal field of view (
width_anglein the figure below) - Vertical field of view
- Image dimension, given by
- frame_size[0], which is the width of the image and
- frame_size[1], the height of the image.
- The distance to the object is estimated thanks to the disparity map
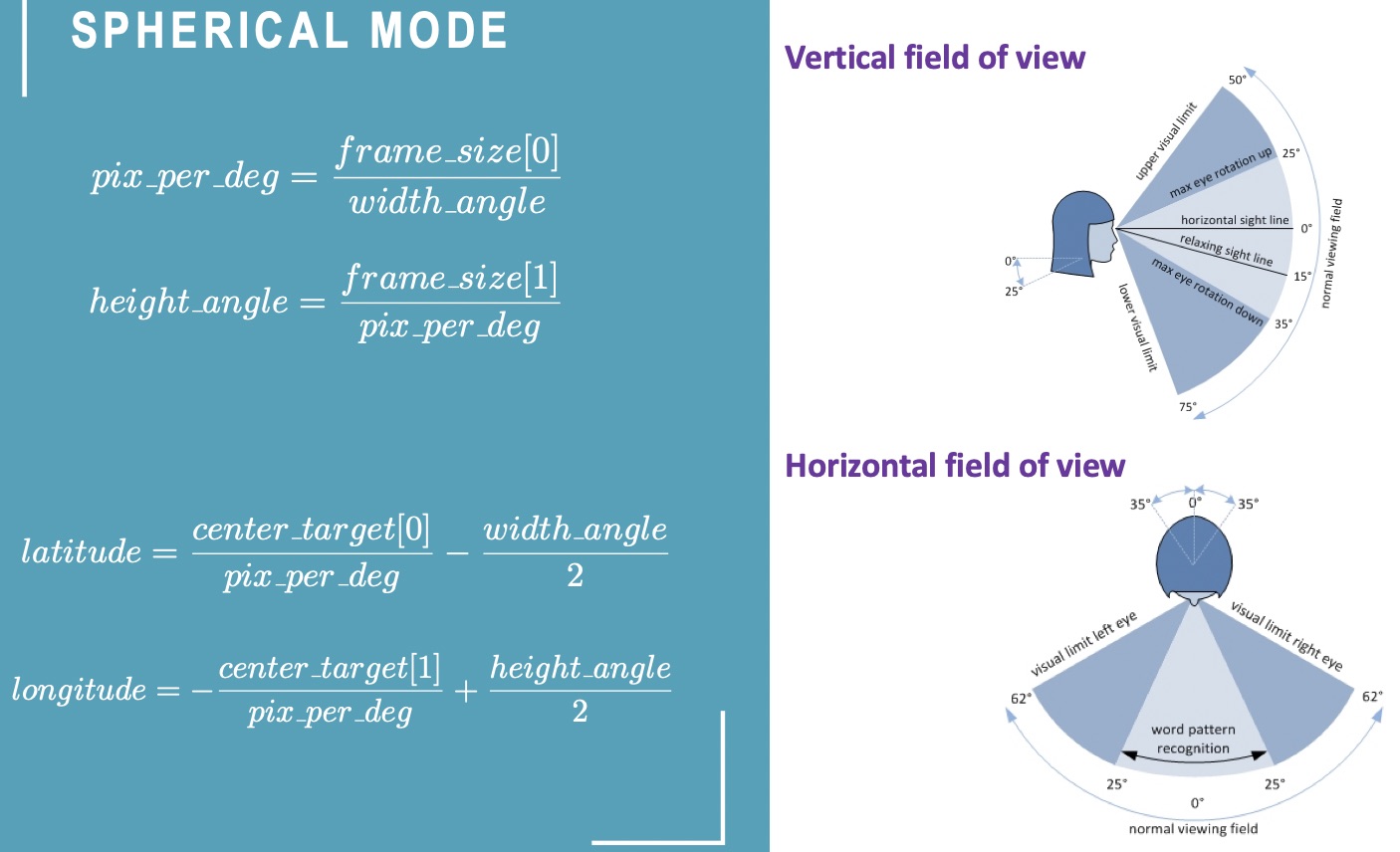
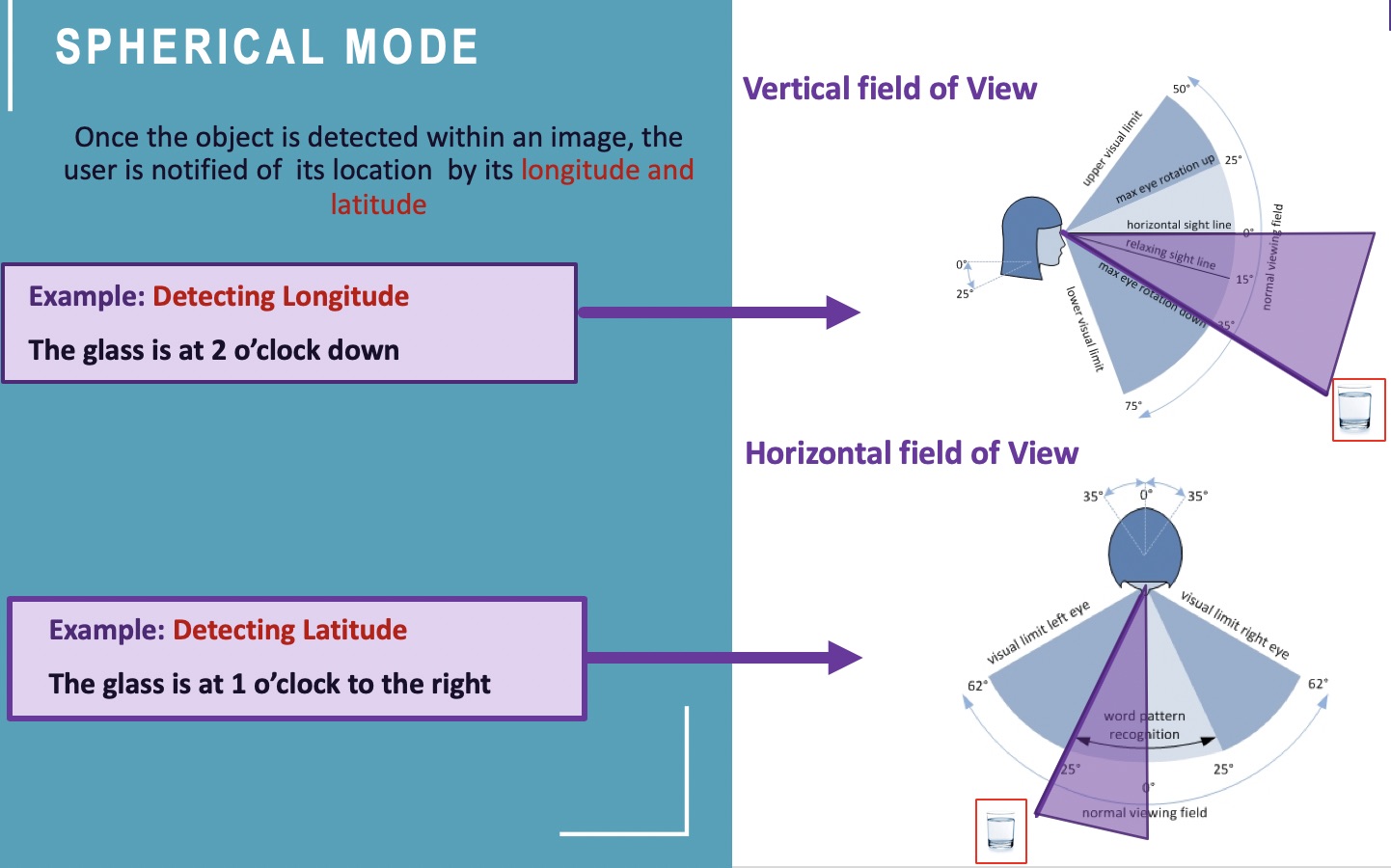
Figure explaining how the latitude and longitude angles are calculated

Screenshot of the Spherical mode in action: The red cross represent the center of the image. The blue cross is the center of the target.
On the above screenshot, one can observe a message on the botton left part. The information the user hears through the text to speech algorithm is translated as follows
- At 2 hours up
- At 1 hour to the right
We chose to provide the user with a clock description, although it is still approximate. We thought that it would be more straightforward than saying that the object is at 60 degrees up and 30 degrees right.
Echo Mode
This mode works in two successive steps. First, the user holding the smartphone will move slowly and scan the room in search for the object. The later will be guided with a sonar sound in which the frequency is proportional to the angle formed with the target and the direction of the camera (heading).
Targeting Phase:
- Scan the room
- Increasing beep when moving towards the target
- Long beep when correct heading
Approach Phase:
- Start the approach phase
- Longer beep indicates object found
The Echo mode relies on the calculation of the angles used in the Sphere mode to help in the localisation during the targeting phase.
The generated beep Is proportional to the Euclidian distance between the center of the object and the center of the image. It is possible to set a threshold based on the height of the targeted object.